■ Python 3

今回もpandasパッケージについて学習です。

前回は、CSV出力とCSVの読み込みをやってみました。その時に見た下記図を見ると、いろいろなフォーマット形式からの読み込みや書き込みがあるみたいです。
【参考】

- 読み込むときは、「read_*」
- 書き込むときは、「to_*」
で良いので、いろいろなフォーマット(形式)に変換できるようなので、CSV以外も試してみようかなと思います。
◆ json形式
まずはよく使いそうな「JSON形式」。

Series型もDataFrame型も、to_json関数を持っているので、「to_json関数」を使ってjson形式で出力してみると…
[series.json]

[dataframe.json]

どちらもきちんとJSON形式で出力されていました。
続いて、出力したjsonファイルを読み込み直そうと、「read_json関数」で読み込もうとしてみると…

series.jsonファイルを読み込もうとしたら、エラーが発生。
一方、dataframe.jsonファイルのほうは普通に読み込みができました。

原因がわからなくて、pandasのページで仕様を見てみると…
pandas.read_json
- pandas.read_json(path_or_buf, *, orient=None, typ='frame', dtype=None,
- convert_axes=None, convert_dates=True, keep_default_dates=True,
- precise_float=False, date_unit=None, encoding=None, encoding_errors='strict',
- lines=False, chunksize=None, compression='infer', nrows=None,
- storage_options=None, dtype_backend=<no_default>, engine='ujson')[source]
Convert a JSON string to pandas object.
typ{‘frame’, ‘series’}, default ‘frame’ The type of object to recover.
上記を見ていると、typ属性を未指定(省略時)の場合は「frame」つまり「DataFrame型」と解析されてしまうようです。
series.jsonの中身は「Series型」のデータ構造だったので、解析でエラーとなっていたようです。
そのため、read_json関数で読み込む時に、typ属性で「series」を指定して実行してみると…

無事に読み込めました。
◆ html形式
続いてHTML形式。
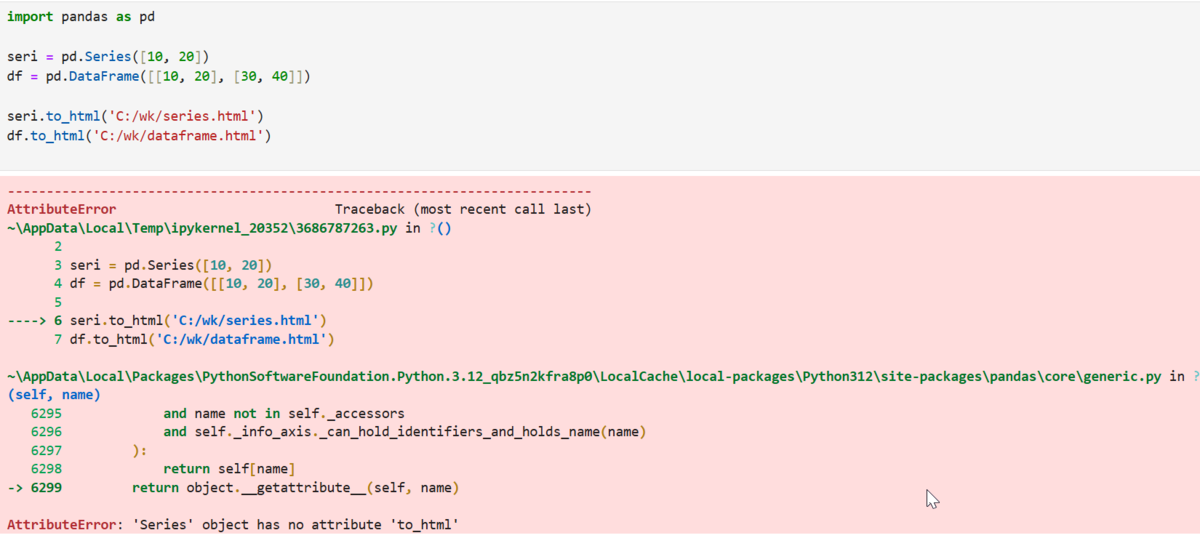
こちらも、「to_html関数」で出力してみると…
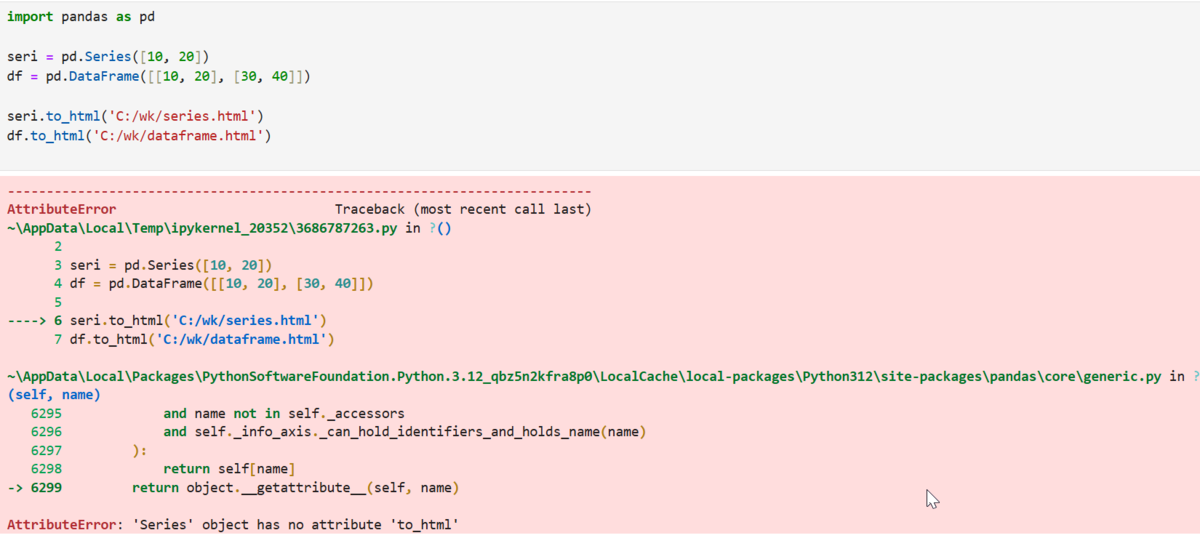
エラーが発生。
エラーメッセージを見ると、「AttributeError: 'Series' object has no attribute 'to_html'」と出ているので、仕様を確認してみると…
確かに、Seriesクラスには「to_html」がありませんでした。
まあ、1次元配列なので、HTML形式にコンバートするメリットはなさそうですからね。
ということで、Series型の方をコメント化して再実行してみると…

DataFrame型はHTML形式で出力できました。

続いて、このファイルを読み込み。
しかし、以下のエラーが発生して読み込めませんでした。
…(中略)...

エラー内容を見ると、
「ImportError: Missing optional dependency 'lxml'. Use pip or conda to install lxml.」
と出ているので、「lxml」パッケージが入っていないことが原因で、「lxml」パッケージをインストールすればよいようです。
ということで、lxmlパッケージをインストール。
!pip install lxml

これで再読込みしてみると…

無事に読み込めました。